
![Cover Image for [BLOG 008] Thực hiện Mô hình cấu trúc SEM (Structural Equation Modeling) bằng ngôn ngữ R](https://cdn.sanity.io/images/rjcymabl/production/017d263af81375a43cdade9d650c8d163b572fd1-1321x532.png?rect=2,0,1319,532&w=1240&h=500)
1. Giới thiệu
Trong bài viết này, tôi sẽ hướng dẫn độc giả sử dụng R để thực hiện SEM. Bài viết dành cho anh chị đã làm quen với ngôn ngữ R từ trước. Nếu có thắc mắc gì, anh chị vui lòng đặt câu hỏi tại bài viết hoặc facebook page SciEco.
Trong thống kê học, Mô hình cấu trúc (SEM) là một công cụ mạnh mẽ được sử dụng để phân tích các mối quan hệ phức tạp giữa các biến. Phương pháp này giúp ta có thể khám phá đồng thời cả tác động nhiều biến số tiềm ẩn.
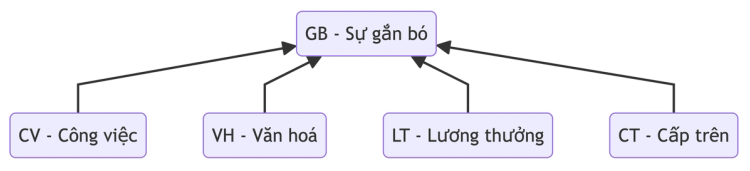
Hãy xem xét ví dụ đơn giản sau đây: sự gắn bó trong công việc của nhân viên tại một công ty do rất nhiều yếu tố, ví dụ môi trường làm việc, đồng nghiệp, cấp trên, áp lực công việc và rất nhiều yếu tố khác. Mục đích của nghiên cứu này là nhằm nghiên cứu các nhân tố ảnh hưởng đến sự gắn bó của nhân viên trong công ty.
Tôi đưa ra giả thuyết rằng 5 yếu tố là công việc, văn hoá công ty, lương thưởng và cấp trên sẽ ảnh hưởng đến sự gắn bó của nhân viên trong công ty, theo sơ đồ bên dưới.
2. Cài đặt thư viện
Ta cài các thư viện cần thiết bằng lệnh sau:
1install.packages(c("psych", "lavaan", "semPlot", "dplyr"))- Thư viện
psych: thực hiện Cronbach’s Alpha, KMO, Bartlett’s Test cho EFA - Thư viện
lavaan: thực hiện CFA và SEM - Thư viện
semPlot: vẽ hình CFA và SEM - Thư viện
dplyr: tiền xử lý dữ liệu
Sau khi cài đặt trong các gói thư viện, ta import các thư viện trên trong phiên làm việc hiện tại bằng lệnh library.
1library(dplyr)
2library(psych)
3library(lavaan)3. Thực hiện import data vào R
Tải số liệu tại link sau: Data
Dữ liệu được lưu trữ trong tệp Excel có tên data.xlsx. Sử dụng thư viện readxl để import dữ liệu vào R.
Lưu ý: Bộ số liệu này chỉ là bộ số liệu được mô phỏng và chỉ được dùng cho mục đích học tập nên không có ý nghĩa trong nghiên cứu thực tế, anh chị không nên sử dụng số liệu hay kết quả này cho các nghiên cứu của mình.
1library(readxl)
2
3# đọc data từ file excel
4data <- read_excel('data.xlsx')
5
6# xem data
7View(data)
4. Tính toán Cronbach’s Alpha
Hệ số Cronbach’s alpha đo lường tính nhất quán bên trong hoặc độ tin cậy của các items trong khảo sát. Cronbach’s alpha được tính theo thang điểm chuẩn hóa từ 0 đến 1.
Giá trị Cronbach’s alpha cao cho thấy phản hồi của mỗi người tham gia khảo sát trong một bộ câu hỏi là nhất quán. Ví dụ: khi người tham gia đưa ra phản hồi cao cho một trong các mục này, họ cũng có khả năng đưa ra phản hồi cao cho các mục khác. Tính nhất quán cho thấy các phép đo là đáng tin cậy và các hạng mục có thể đo lường cùng một đặc trưng.
Ta thực hiện tính Cronbach’s Alpha cho nhóm yếu cố Công việc - CV.
1data %>%
2 select(CV1:CV5) %>% # chọn cột CV1 đến CV5
3 psych::alpha() # tính Cronbach's alpha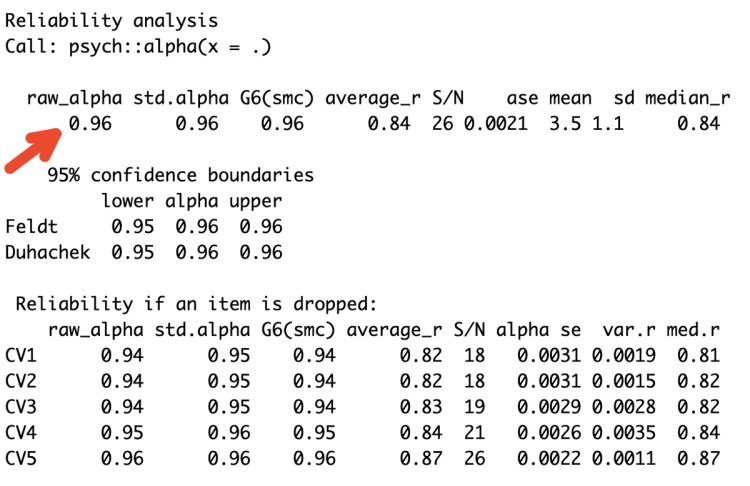
Ta tính được Cronbach’s alpha cho nhóm Công việc là 0.96.
Thực hiện tương tự cho các nhóm Văn hoá - VH, Lương thưởng - LT, Cấp trên - CT và Sự gắn bó - GB, ta được kết quả sau:
- VH: 0.96
- LT: 0.96
- CT: 0.96
- GB: 0.91
5. Thực hiện EFA
Phân tích nhân tố khám phá (EFA) được các nhà nghiên cứu sử dụng khi phát triển một thang đo để đo lường một chủ đề nghiên cứu cụ thể.
Cụ thể EFA dùng để xác định các nhân tố tiềm ẩn làm nền tảng cho một nhóm các biến được đo. Phương pháp này được sử dụng khi nhà nghiên cứu không có giả thuyết tiên nghiệm về các yếu tố hoặc mô hình của các biến đo được.
Yêu cầu cho phương pháp EFA
- KMO Statistics > 0.9
- Bartlett’s Test for Sphericity < 0.05 (Mức ý nghĩa)
- Communalities > 0.4
Ta thực hiện các kiểm tra KMO và kiểm định Bartlett, trước hết ta cần loại bỏ nhóm câu hỏi về sự gắn bó GB vì theo giả thuyết thì đây là biến phụ thuộc nên ta sẽ không thực hiện cho nhóm này.
1# loại bỏ các biến GB1, GB2, ...
2X_df <- select(data, -starts_with("GB"))Ta thực hiện KMO với data frame X_df.
1KMO(X_df)
Kết quả KMO tính ra được tại dòng Overall MSA, ta thấy KMO là 0.9, thoả mãn điều kiện.
Tiếp tục ta thực hiện kiểm định Bartlett, cho ra kết quả p-value < 0.05, thoả mãn điều kiện.
1bartlett.test(X_df)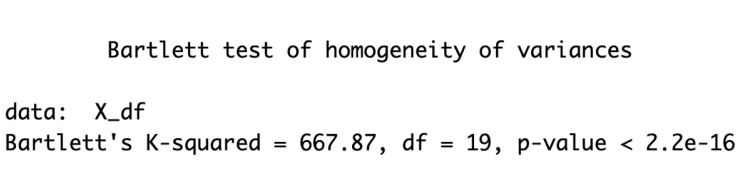
Mục đích của EFA
- Giúp xác định số lượng nhân tố (factor) từ tập hợp các biến đầu vào
- Giúp loại bỏ các câu hỏi (item) không tốt
- Giúp xác định các nhóm câu hỏi thuộc các factor được chỉ định, các câu không liên quan tới nhóm factor sẽ được loại ra
Việc chọn và phân loại các item theo các factor được dựa vào loadings, trong đó mức loading của 1 item với 1 factor càng cao thì item đó sẽ càng liên quan tới item đó, mức để loại và giữ item của 1 factor được xác định tuỳ theo cỡ mẫu (sample size), cụ thể theo bảng sau:
Sample Size | Sufficient Factor Loading |
50 | 0.75 |
60 | 0.70 |
70 | 0.65 |
85 | 0.60 |
100 | 0.55 |
120 | 0.50 |
150 | 0.45 |
200 | 0.40 |
250 | 0.35 |
≥ 350 | 0.30 |
Ta thực hiện EFA với X_df với nfactors là số lượng factor giả định là 4. Vì ví dụ này có số lượng quan sát lớn, nên ta thực hiện cutoff tại mức 0.3.
1efa(X_df, nfactors = 4, rotation = "varimax", output = "efa") %>%
2 summary(cutoff = 0.3)Discriminant validity cập đến việc việc factor phải độc lập và không tương quan.
Quy tắc là các item phải liên quan chặt chẽ đến factor của chính chúng hơn là các factor khác. Các item chỉ nên có loading lớn trên một factor. Nếu "cross-loadings" tồn tại (loading lớn trên nhiều factor) thì độ trên lệch loading của các factor trên 1 item phải lớn hơn 0,2.
Ta có thể thấy từ bảng standardized loadings bên dưới, loading của các item chỉ lớn ở 1 factor. Như vậy thang đo này đã thoả mãn discriminant validity. Ngoài ra tại cột communalities, ta thấy tất cả đều lớn hơn 0.4 như vậy thoả mãn yêu cầu của EFA.
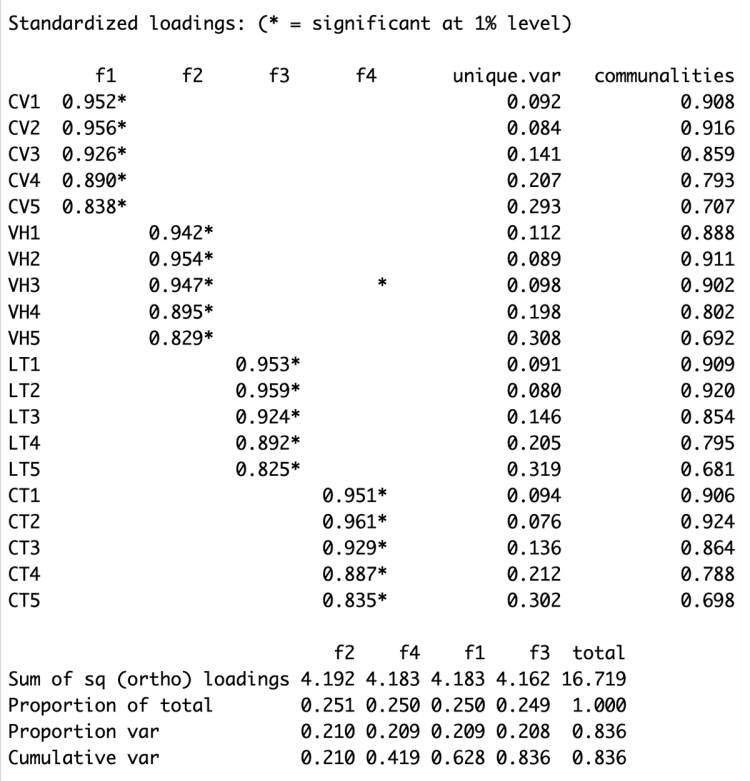
Tại dòng Cummulative var, ta thấy được với 4 factor được trích xuất, ta đã giải thích được 83,6% phương sai của dữ liệu ban đầu (như vậy thoả mãn yêu cầu về khả năng giải thích là trên 50%).
Hiểu sai thường thấy trong thực hiện EFA và CFA
Nhiều nghiên cứu thường theo quy trình Cronbach's Alpha, EFA, CFA, SEM do đó lầm tưởng rằng EFA luôn phải được thực hiện trước CFA.
- EFA: Phân tích khám phá, xác định số lượng và cấu trúc nhân tố tiềm ẩn. Ta dùng khi chưa có giả định về cấu trúc nhân tố.
- CFA: Phân tích khẳng định, đánh giá tính hợp lý của cấu trúc nhân tố giả định. Ta dùng khi đã có giả định về cấu trúc nhân tố từ trước.
Do đó: EFA là không bắt buộc nếu bạn đã có giả định rõ ràng về cấu trúc nhân tố (tham khảo mô hình từ nghiên cứu trước). EFA chỉ cần thiết khi bạn muốn khám phá cấu trúc nhân tố tiềm ẩn của dữ liệu, còn CFA dùng để xác nhận lại cấu trúc của các factor đã có từ trước được bạn tham khảo và sử dụng lại.
Nguồn tham khảo: https://www.researchgate.net/post/Can_we_perform_EFA_before_we_confirm_the_model_via_CFA
6. Thực hiện CFA
Phân tích nhân tố khẳng định (CFA) là bước tiếp theo sau phân tích nhân tố khám phá để xác định cấu trúc nhân tố của tập dữ liệu. Trong EFA khám phá cấu trúc nhân tố (các biến liên quan như thế nào và nhóm dựa trên mối tương quan giữa các biến); trong CFA xác nhận cấu trúc nhân tố được trích xuất trong EFA. (Brow, 2014)
CFA sử dụng các chỉ số để đánh giá mức độ phù hợp của mô hình (goodness of fit). Một số chỉ số được sử dụng như sau (Hair et al., 2010, Hu ad Bentler, 1999).
Measure | Threshold |
Chi-square/df (cmin/df) | < 3 tốt, < 5 chấp nhận được |
p-value của mô hình | > 0.05 |
CFI, TLI | > 0.95 (tốt), > 0.90 (chấp nhận được) |
SRMR | < 0.09 |
RMSEA | < 0.05 tốt, 0.05 - 0.01 (chấp nhận được) |
PCLOSE | > 0.05 |
Thực hiện khai báo mô hình cho CFA, trong đó =~ dùng để khai báo cho các yếu tố tiềm ẩn (factor), lưu ý các item trong vế phải có trong dataset.
1cfa.model <- '
2 GB =~ GB1 + GB2 + GB3 + GB4 + GB5
3 CV =~ CV1 + CV2 + CV3 + CV4 + CV5
4 VH =~ VH1 + VH2 + VH3 + VH4 + VH5
5 LT =~ LT1 + LT2 + LT3 + LT4 + LT5
6 CT =~ CT1 + CT2 + CT3 + CT4 + CT5
7'Thực hiện tính toán CFA bằng hàm cfa trong thư viện lavaan.
1cfa.fit <- cfa(cfa.model, data=data)Hiển thị kết quả tính toán CFA, ta thêm standardized=TRUE và fit.measures=TRUE để hiển thị toàn bộ các tính toán được chuẩn hoá và các chỉ số về mức độ phù hợp của mô hình được đề cập ở bên trên.
1summary(
2 cfa.fit,
3 standardized=TRUE,
4 fit.measures=TRUE
5)
Để lấy ra các chỉ số về độ phụ hợp mô hình, ta sử dụng hàm fitMeasures và truyền và các chỉ số cần lấy, nếu ta không truyền vào thì hàm sẽ trả về toàn bộ chỉ số tính toán được.
Dựa vào kết quả tính toán được, ta thấy rằng tất cả các chỉ số này đều thoả mãn tốt yêu cầu của phân tích CFA.
1fitMeasures(cfa.fit, c("cfi", "tli", "gfi", "rmsea", "srmr"))
2# cfi tli gfi rmsea srmr
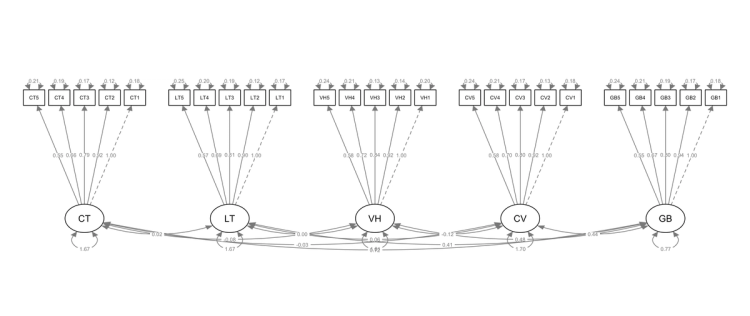
3# 0.981 0.979 0.930 0.046 0.020Ta thực hiện vẽ đồ thị của CFA bằng hàm semPaths.
1semPaths(
2 cfa.fit,
3 whatLabels = "est",
4 edge.label.cex = 0.5,
5 rotation = 3,
6 sizeMan = 3.3,
7 sizeLat = 6,
8 layoutSplit = TRUE
9)
7. Thực hiện SEM
Structural Equation Modeling - SEM là một khung mô hình tuyến tính nhằm mô hình hoá cả hai phương trình hồi quy đồng thời với các biến tiềm ẩn.
SEM kết hợp một loạt các phương pháp như multivariate regression, path analysis, confirmatory factor analysis. Các mối quan hệ sau đây có thể có trong SEM:
- Regression: Biến quan sát → Biến quan sát (observed to observed variables)
- CFA: Biến tiềm ẩn → Biến quan sát (latent to observed variables)
- Structural regression: Biến tiềm ẩn → Biến tiềm ẩn (latent to latent variables)
Các thành phần của SEM được mô tả theo hình sau, tìm hiểu thêm tại đây.
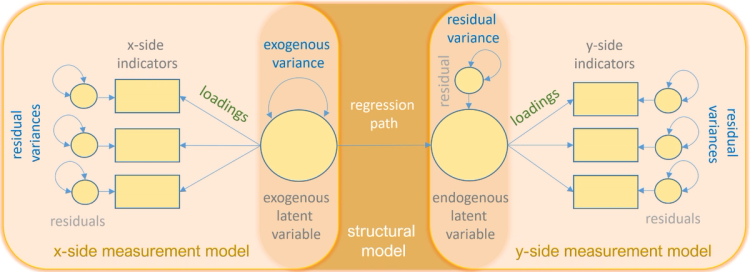
Nguồn tham khảo: Introduction to Stuctural Equation Modeling (SEM) in R with lavaan. UCLA: Statistical Consulting Group. from https://stats.oarc.ucla.edu/r/seminars/rsem/ (accessed April 20, 2024).
Để thực hiện SEM, ta cần khai báo mô hình. Cụ thể ta có 5 biến tiềm ẩn trong có GB là biến phụ thuộc và các biến còn lại là biến độc lập. Ta sử dụng =~ để khai báo cho biến tiềm ẩn tương tự CFA. Đối với phương trình hồi quy, ta sử dụng ~ để khai báo mối liên hệ giữa GB và các biến tiềm ẩn còn lại.
1sem.model <- '
2 GB =~ GB1 + GB2 + GB3 + GB4 + GB5
3 CV =~ CV1 + CV2 + CV3 + CV4 + CV5
4 VH =~ VH1 + VH2 + VH3 + VH4 + VH5
5 LT =~ LT1 + LT2 + LT3 + LT4 + LT5
6 CT =~ CT1 + CT2 + CT3 + CT4 + CT5
7 GB ~ CV + VH + LT + CT
8'Sau khi thực hiện khai báo mô hình, ta thực hiện tính toán bằng hàm sem, sau đó xem kết quả bằng hàm summary
1sem.fit <- sem(sem.model, data=data, meanstructure=TRUE)
2summary(sem.fit)Ta thêm tham số meanstructure=TRUE để mô hình xét tới hệ số gốc (intercept), mặc định R sẽ bỏ qua thành phần này trong mô hình.
Để xem thêm thông tin về các chỉ số độ phù hợp mô hình như (CFI, TLI, GFI, …) ta thêm tham số fit.measures = TRUE, và tham số standardized=TRUE để có được các hệ số chuẩn hoá.
1summary(mod.est, fit.measures = TRUE, standardized=TRUE)Phân tích kết quả mô hình
Đầu tiên tại bảng kết quả hồi quy, ta thấy được tại cột Estimate là hệ số hồi quy được tính toán ra, ta thấy rằng các hệ số này đều dương đồng thời tại cột P(>|z|) là p.value của các hệ số ta thấy đều nhỏ tức đạt ý nghĩa thống kê.
Như vậy ta thấy được có mối liên hệ tích cực giữa các yếu tố như công việc, văn hoá, lương thưởng và cấp trên ảnh hưởng đáng tích cực (có ý nghĩa thống kê) đến sự gắn bó của nhân viên, ví dụ cấp trên thân thiện hoặc lương cao sẽ làm nhân viên càng thêm gắn bó hơn trong công việc.
Ta để ý tại cột Std.all là hệ số hồi quy chuẩn hoá, điểm đặc biệt của hệ số này là ta có thể so sánh giữa các hệ số của các biến với nhau để xác định mức độ quan trọng của các biến. Ta thấy được trong 4 yếu tố thì cấp trên đóng vai trong trọng nhất đến sự gắn bó của nhân viên (có hệ số lớn nhất là 0.658).
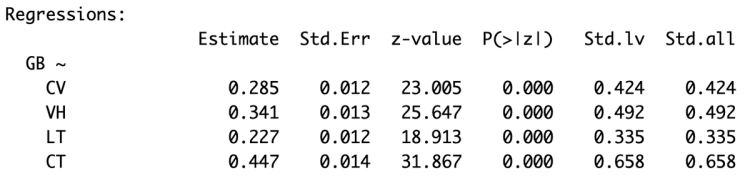
Chỉ số Model Fit
Ta lấy các chỉ số model fit của mô hình bằng hàm fitMeasures.
1fitMeasures(sem.fit, c("cfi", "tli", "gfi", "rmsea", "srmr"))
2# cfi tli gfi rmsea srmr
3# 0.981 0.979 0.993 0.046 0.020Ta thấy rằng chỉ số trả về chính là các chỉ số tính được tại bước CFA.
1fitMeasures(cfa.fit, c("cfi", "tli", "gfi", "rmsea", "srmr"))
2# cfi tli gfi rmsea srmr
3# 0.981 0.979 0.993 0.046 0.020Một điểm đang chú ý ở đây là vì SEM có sử dụng kĩ thuật CFA trong tính toán nên khi ta đã thực hiện kiểm tra tại bước CFA thì kết quả vẫn tương tự cho bước tính toán SEM, mặc dù cho mô hình ta có khai báo cho bước CFA và SEM là khác nhau.
1cfa.model <- '
2 GB =~ GB1 + GB2 + GB3 + GB4 + GB5
3 CV =~ CV1 + CV2 + CV3 + CV4 + CV5
4 VH =~ VH1 + VH2 + VH3 + VH4 + VH5
5 LT =~ LT1 + LT2 + LT3 + LT4 + LT5
6 CT =~ CT1 + CT2 + CT3 + CT4 + CT5
7'
8
9sem.model <- '
10 GB =~ GB1 + GB2 + GB3 + GB4 + GB5
11 CV =~ CV1 + CV2 + CV3 + CV4 + CV5
12 VH =~ VH1 + VH2 + VH3 + VH4 + VH5
13 LT =~ LT1 + LT2 + LT3 + LT4 + LT5
14 CT =~ CT1 + CT2 + CT3 + CT4 + CT5
15 GB ~ CV + VH + LT + CT
16'Biểu đồ SEM
Bước cuối cùng là trực quan hóa mô hình bằng biểu đồ SEM. Sử dụng thư viện semPlot để vẽ biểu đồ với các tùy chọn khác nhau.
1semPaths(
2 sem.fit,
3 whatLabels = "est",
4 edge.label.cex = 0.4,
5 rotation = 2,
6 sizeMan = 3,
7 sizeLat = 5,
8 layoutSplit = F,
9 mar = c(1,1,1,1)
10)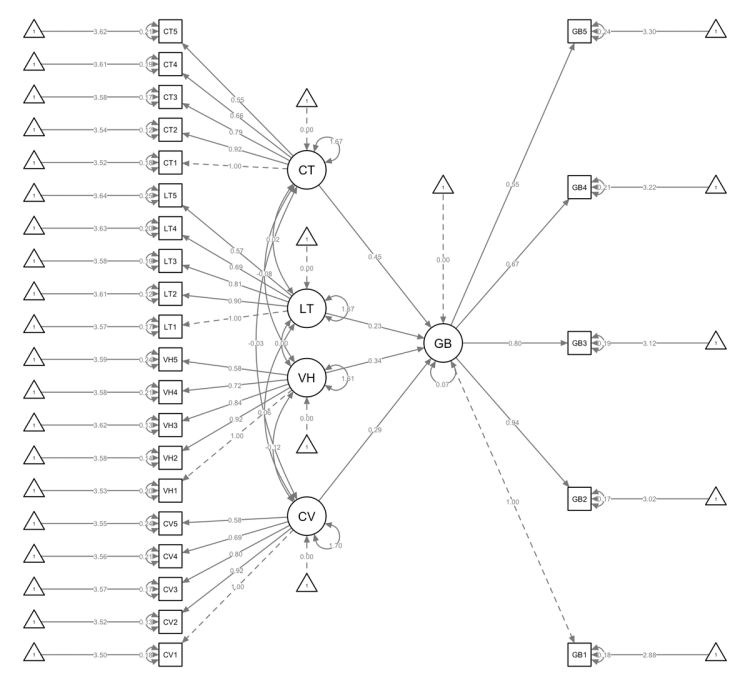
Biểu đồ cung cấp biểu diễn hình học của mô hình SEM. Nó phân biệt các biến quan sát (được bao bọc trong hình vuông hoặc hình chữ nhật) với các biến tiềm ẩn (được biểu thị bằng hình tròn hoặc hình elip)
Đường tên mũi tên ở một đầu hay còn gọi là đường đi biểu thị mối quan hệ nhân quả giữa các biến. Những đường dẫn này giúp chúng ta hiểu cách các biến tương tác trong mô hình.
Hệ số gốc (intercept) biểu thị bằng hình tam giác, và hệ số gốc được ước lượng được biểu thị bằng con số nằm trên đường mũi tên nối từ các tác giác này
Mũi tên hai đầu biểu thị hiệp phương sai giữa các biến. Khi hai biến được kết nối bằng mũi tên hai đầu, điều đó cho thấy chúng có chung một yếu tố cơ bản hoặc có liên quan trực tiếp với nhau. Mũi tên hai đầu chỉ vào cùng một biến phản ánh các phương sai của biến đó.
8. Kết luận
Bài đăng đã giải thích chi tiết về cách triển khai Mô hình phương trình cấu trúc (SEM) trong R. Chúng tôi đã trình bày các bước liên quan, bao gồm nhập dữ liệu, Cronbach’s Alpha, CFA và SEM (cụ thể là chỉ định mô hình, ước tính tham số và vẽ sơ đồ).
Bằng cách tận dụng SEM trong R, các nhà nghiên cứu có thể hiểu sâu hơn về các mối quan hệ phức tạp và đưa ra quyết định sáng suốt dựa trên kết quả từ mô hình.


